In today’s hyper-competitive business landscape, sales leaders face a relentless challenge: how to drive growth, outpace competitors, and make smarter decisions faster in a resource constrained environment. Thankfully, the promise of AI in sales is no longer theoretical. With the advent of agentic solutions embedded in Microsoft Dynamics 365 Sales, including the Sales Research Agent, organizations are witnessing a transformation in how business decisions are made, and teams are empowered. But how do you know if these breakthrough technologies have reached a level of quality where you can trust them to support business-critical decisions?
Today, I’m excited to share an update on the Sales Research Agent, in public preview as of October 1, as well as a new evaluation benchmark, the Microsoft Sales Research Bench, created to assess how AI solutions respond to the strategic, multi-faceted questions that sales leaders have about their business and operational performance. We intend to publish the full evaluation package behind the Sales Research Bench in the coming months so that others can run these evals on different AI solutions themselves.
The New Frontier: AI Research Agents in Sales
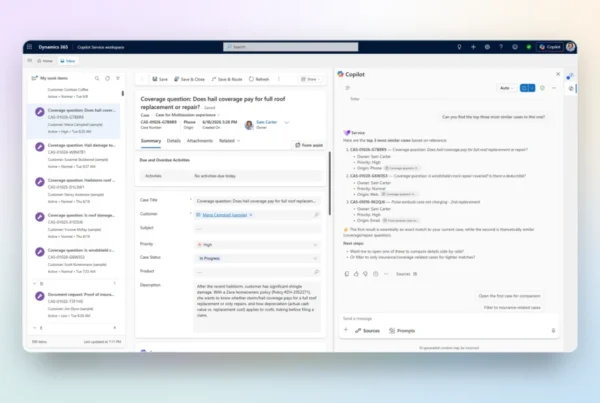
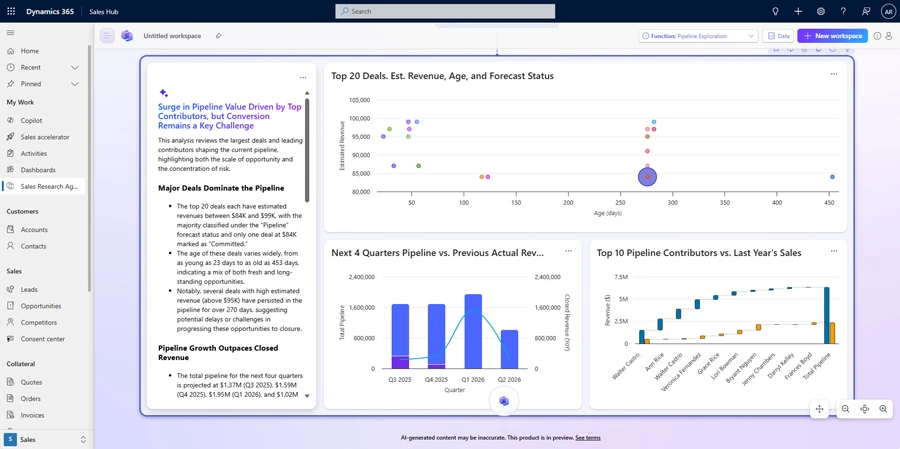
Sales Research Agent in Dynamics 365 Sales empowers business leaders to explore complex business questions through natural language conversations with their data. It leverages a multi-modal, multi-model, and multi-agent architecture to reason over intricate, customized schemas with deep sales domain expertise. The agent delivers novel, decision-ready insights through narrative explanations and rich visualizations tailored to the specific business context.
For sales leaders, this means the ability to self-serve on real-time trustworthy analysis, spanning CRM and other domains, which previously took many people days or weeks to compile, with access to deeper insights enabled by the power of AI on pipeline, revenue attainment, and other critical topics.
Image: Screenshot of the Sales Research Agent in Dynamics 365 Sales
“As a product manager in the sales domain, balancing deep data analysis with timely insights is a constant challenge. The pace of changing market dynamics demands a new way to think about go-to-market tactics. With the Sales Research Agent, we’re excited to bridge the gap between traditional and time-intensive reporting and real-time, AI-assisted analysis — complementing our existing tools and setting a new standard for understanding sales data.“
Kris Kuty, EY LLP
Clients & Industries — Digital Engagement, Account, and Sales Excellence Lead
What makes the Sales Research Agent so unique?
- Its turnkey experience goes beyond the standard AI chat interface to provide a complete user experience with text narratives and data visualizations tailored for business research and compatible with a sales leader’s natural business language.
- As part of Dynamics 365 Sales, it automatically connects to your CRM data and applies schema intelligence to your customizations, with the deep understanding of your business logic and the sales domain that you’d expect a business application to have.
- Its multi-agent, multi-model architecture enables the Sales Research Agent to build out a dedicated research plan and to delegate each task to specialized agents, using the model best suited for the task at hand.
- Before the agent shares its business assessment and analysis, it critiques its work for quality. If the output does not meet the agent’s own quality bar, it will revise its work.
- The agent explains how it arrived at its answers using simple language for business users and showing SQL queries for technical users, enabling customers to quickly verify its accuracy.
Why Verifiable Quality Matters
Seemingly every day a new AI tool shows up. The market is crowded with offers that may or may not deliver acceptable levels of quality to support business decisions. How do you know what’s truly enterprise ready? To help make sure business leaders do not have to rely on anecdotal evidence or “gut feel”, any vendor providing AI solutions needs to earn trust through clear, repeatable metrics that demonstrate quality, showing where the AI excels, where it needs improvement, and how it stacks up against alternatives.
While there is a wide range of pioneering work on AI evaluation, enterprises deserve benchmarks that are purpose-built for their needs. Existing benchmarks don’t reflect 1) the strategic, multi-faceted questions of sales leaders using their natural business language; 2) the importance of schema accuracy; or 3) the value of quality across text and visualizations. That is why we are introducing the Sales Research Bench.
Introducing Sales Research Bench: The Benchmark for AI-powered Sales Research
Inspired by groundbreaking work in AI Benchmarks such as TBFact and RadFact, Microsoft developed the Sales Research Bench to assess how AI solutions respond to the business research questions that sales leaders have about their business data.1
Read this blog post for a detailed explanation of the Sales Research Bench methodology as well as the Sales Research Agent’s architecture.
This benchmark is based on our customers’ real-life experiences and priorities. From engagements with customer sales teams across industries and around the world, Microsoft created 200 real-world business questions in the language sales leaders use and identified 8 critical dimensions of quality spanning accuracy, relevance, clarity, and explainability. The data schema on which the evaluations take place is customized to reflect the complexities of our customers’ enterprise environments, with their layered business logic and nuanced operational realities.
To illustrate, here are 3 of our 200 evaluation questions informed by real sales leader questions:
- Looking at closed opportunities, which sellers have the largest gap between Total Actual Sales and Est Value First Year in the ‘Corporate Offices’ Business Segment?
- Are our sales efforts concentrated on specific industries or spread evenly across industries?
- Compared to my headcount on paper (30), how many people are actually in seat and generating pipeline?
Judging is handled by LLM evaluators that rate an AI solution’s responses (text and data visualizations) against each quality dimension on a 100-point scale based on specific guidelines (e.g., give score of 100 for chart clarity if the chart is crisp and well labeled, score of 20 if the chart is unreadable, misleading). These dimension-specific scores are then weighted to produce a composite quality score, with the weights defined based on qualitative input from customers, what we have heard customers say they value most. The result is a rigorous benchmark presenting a composite score and dimension-specific scores to reveal where agents excel or need improvement.[2]
[1] For more on TBFact: Towards Robust Evaluation of Multi-Agent Systems in Clinical Settings | Microsoft Community Hub and for more on RadFact: [2406.04449] MAIRA-2: Grounded Radiology Report Generation
[2] Sales Research Bench uses Azure Foundry’s out-of-box LLM evaluators for the dimensions of Text Groundedness and Text Relevance. The other 6 dimensions each have a custom LLM evaluator that leverages Open AI’s GPT 4.1 model. 100-pt scale has 100 as the highest score with 20 as the lowest. More details on the benchmark methodology are provided here
Running Sales Research Bench on AI solutions
Here’s how we applied the Sales Research Bench to run evaluations on the Sales Research Agent, ChatGPT by OpenAI, and Claude by Anthropic.
- License: Microsoft evaluated ChatGPT by OpenAI using a Pro license with GPT-5 in Auto mode and Claude Sonnet 4.5 by Anthropic using a Max license. The licenses were chosen to optimize for quality: ChatGPT’s pricing page describes Pro as “full access to the best of ChatGPT,” while Claude’s pricing page recommends Max to “get the most out of Claude.”3 Similarly, ChatGPT’s evaluation was run using Auto mode, a setting that allows ChatGPT’s system to determine the best-suited model variant for each prompt.
- Questions: All agents were given the same 200 business questions.
- Instructions: ChatGPT and Claude were given explicit instructions to create charts and to explain how they got to their answers. (Equivalent instructions are included in the Sales Research Agent out of box.)
- Data: ChatGPT and Claude accessed the sample dataset in an Azure SQL instance exposed through the MCP SQL connector. The Sales Research Agent connects to the sample dataset in Dynamics 365 Sales out of box.
3ChatGPT Pricing and Pricing | Claude, both accessed on October 19, 2025
Results are in: Sales Research Agent vs. alternative offerings
In head-to-head evaluations completed on October 19, 2025 using the Sales Research Bench framework, the Sales Research Agent outperformed Claude Sonnet 4.5 by 13 points and ChatGPT-5 by 24.1 points on a 100-point scale.
Image: Sales Research Agent – Evaluation Results
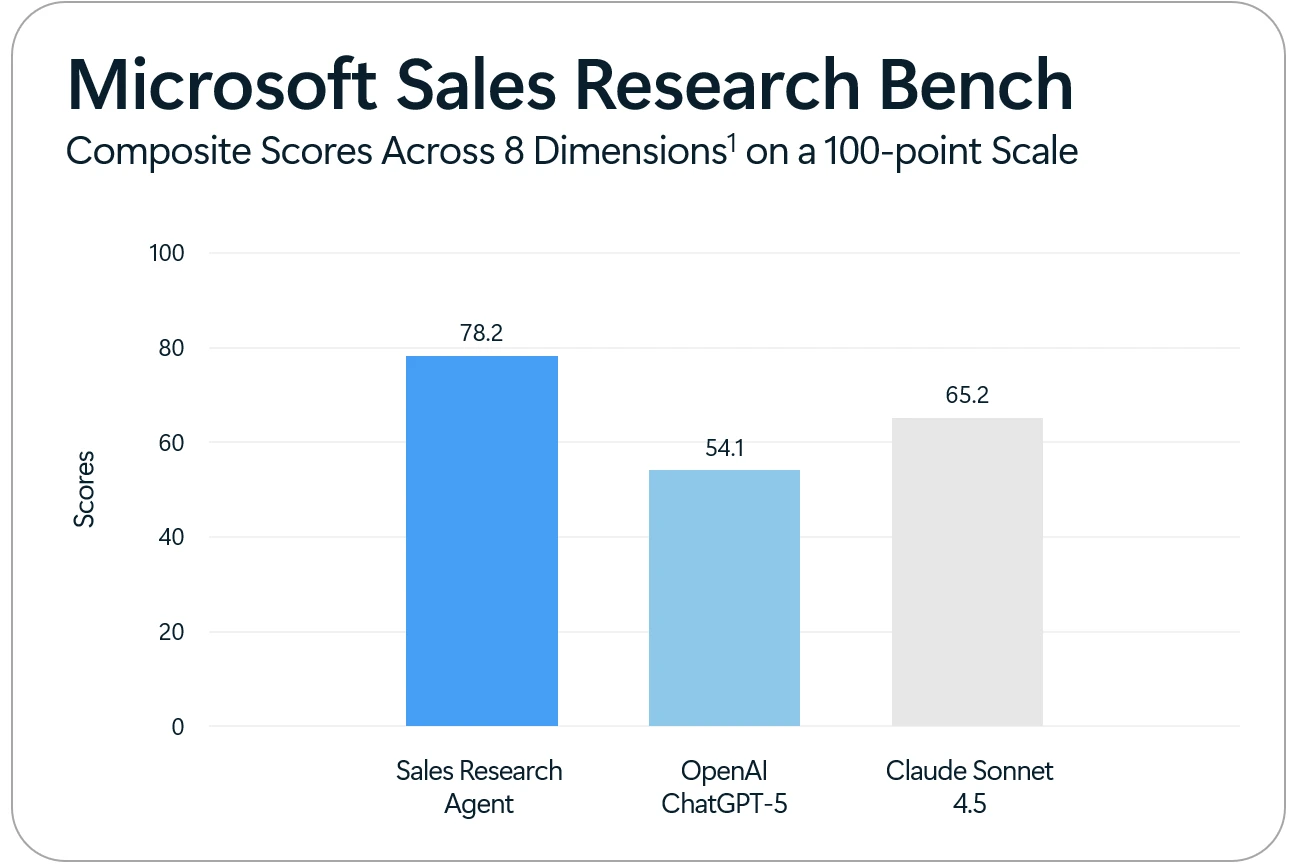
1Results: Results reflect testing completed on October 19, 2025, applying the Sales Research Bench methodology to evaluate Microsoft’s Sales Research Agent (part of Dynamics 365 Sales), ChatGPT by OpenAI using a ChatGPT Pro license with GPT-5 in Auto mode, and Claude Sonnet 4.5 by Anthropic using a Claude Max license.
Methodology and Evaluation dimensions: Sales Research Bench includes 200 business research questions relevant to sales leaders that were run on a sample customized data schema. Each AI solution was given access to the sample dataset using different access mechanisms that aligned with their architecture. Each AI solution was judged by LLM judges for the responses the solution generated to each business question, including text and data visualizations.
We evaluated quality based on 8 dimensions, weighting each according to qualitative input from customers, what we have heard customers say they value most in AI tools for sales research: Text Groundedness (25%), Chart Groundedness (25%), Text Relevance (13%), Explainability (12%), Schema Accuracy (10%), Chart Relevance (5%), Chart Fit (5%), and Chart Clarity (5%). Each of these dimensions received a score from an LLM judge from 20 as the worst rating to 100 as the best. For example, the LLM judge would give a score of 100 for chart clarity if the chart is crisp and well labeled, score of 20 if the chart is unreadable or misleading. Text Groundedness and Text Relevance used Azure Foundry’s out-of-box LLM evaluators, while judging for the other six dimensions leveraged Open AI’s GPT 4.1 model with specific guidance. A total composite score was calculated as a weighted average from the 8 dimension-specific scores. More details on the methodology can be found in this blog.
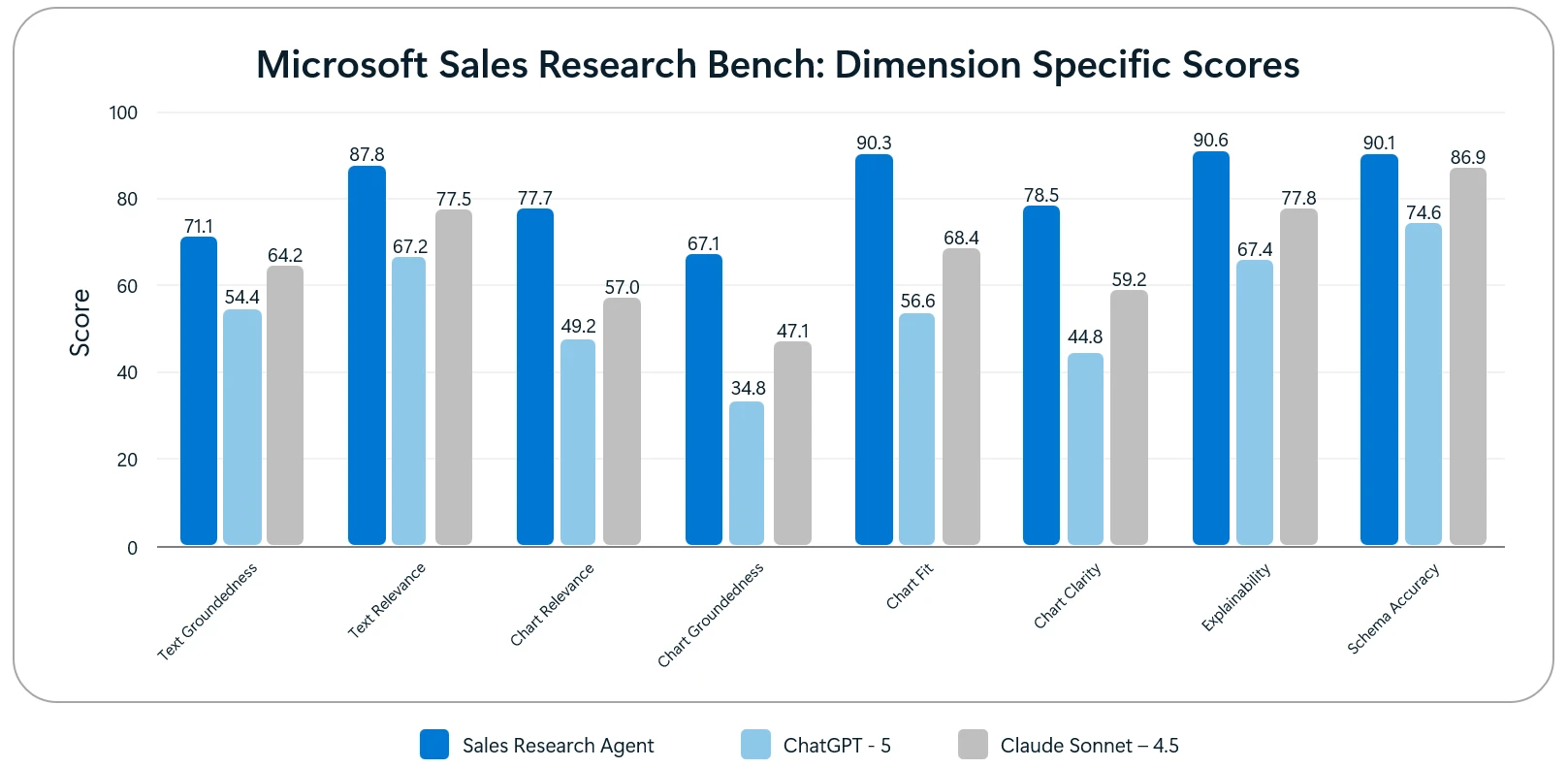
The Sales Research Agent outperformed these solutions on each of the 8 quality dimensions.
Image: Evaluation Scores for Each of the Eight Dimensions
The Road Ahead: Investing in Benchmarks
Upcoming plans for the Sales Research Bench include using the benchmark for continuous improvement of the Sales Research Agent, running comparisons against a wider range of competitive offerings, and publishing the full evaluation package including all 200 questions and the sample dataset in the coming months, so that others can run it themselves to verify the published results and benchmark the agents they use. Evaluation is not a one-time event. Scores can be tracked across releases, domains, and datasets, driving targeted quality improvements and ensuring the AI evolves with your business.
Sales Research Bench is just the beginning. Microsoft plans to develop eval frameworks and benchmarks for more business functions and agentic solutions—in customer service, finance, and beyond. The goal is to set a new standard for trust and transparency in enterprise AI.
Why This Matters for Sales Leaders
For business decision makers, the implications are profound:
- Accelerated Decision-Making: AI-driven insights you can trust, when delivered in real time, enable faster, more confident decisions
- Continuous Improvement: Thanks to evals, developers can quickly identify areas for highest measurable impact and focus improvement efforts there
- Trust and Transparency: Rigorous evaluation means you can rely on the outputs, knowing they’ve been tested against the scenarios that matter most to your business.
The future of sales is agentic, data-driven, and relentlessly focused on quality. With Microsoft’s Sales Research Agent and the Sales Research Bench evaluation framework, sales leaders can move beyond hype and make decisions grounded in demonstration of quality. It’s not just about having the smartest AI—it’s about having a trustworthy partner for your business transformation.